DynamoDB backup to a different AWS account
by Mahesh Kumar Kolla
One of the well known ways to backup AWS DynamoDB is to use Data Pipelines and EMR. But there are few disadvantages with this approach like creation of temporary EC2 instance, using provisioned read capacity of the DynamoDB table for backup and it could take a lot of time to backup depends on the size of data, size of EC2 instance and provisioned read capacity etc., Overall this could even lead to high costs and less maintainable.
AWS has released a feature “Export to S3” which solves a lot these problems. This is a complete serverless solution. Hence it is scalable and performant. Exporting feature does not consume provisioned read capacity of the table, as a result it has no impact on the performance and availability of the Dynamo table.
How to backup?
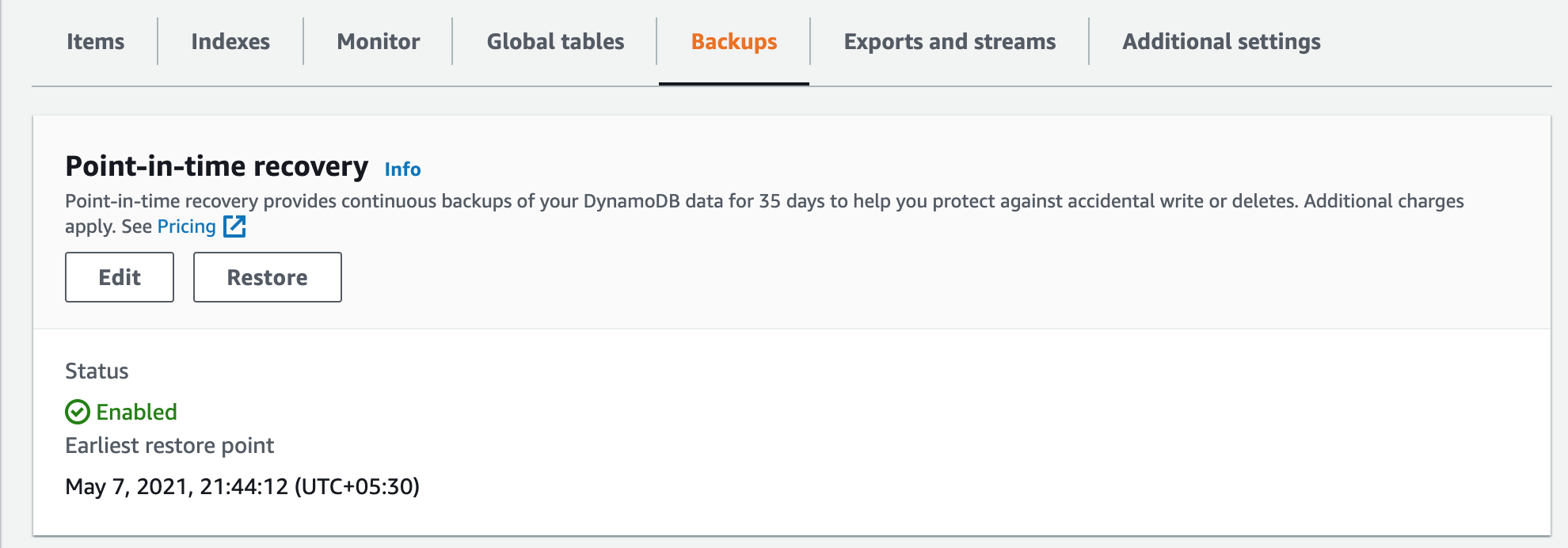
Enable PITR (Point in time recovery)
First we need to enable the PITR (Point in time recovery) on the DynamoDB.
- Go to the Dynamo table in the console
- Navigate to Backups tab
- You see an option to enable to PITR as below image
From Terraform: Add this block to aws_dynamodb_table resource
point_in_time_recovery {
enabled = true
}
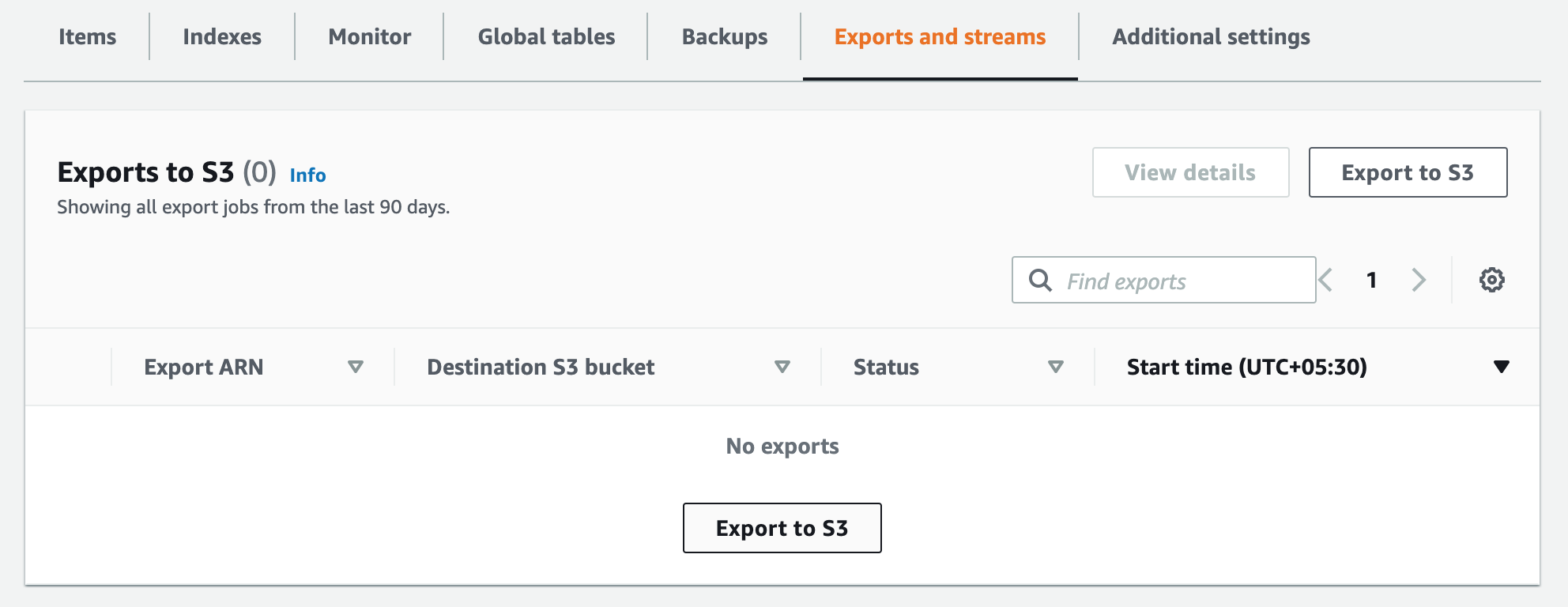
Export to S3
- Go to “Exports and streams” tab in the Dynamo table page
- Click on “Export to S3” button
- Select the S3 bucket where you want to export
- Click on Export button
- You can see the status of the export
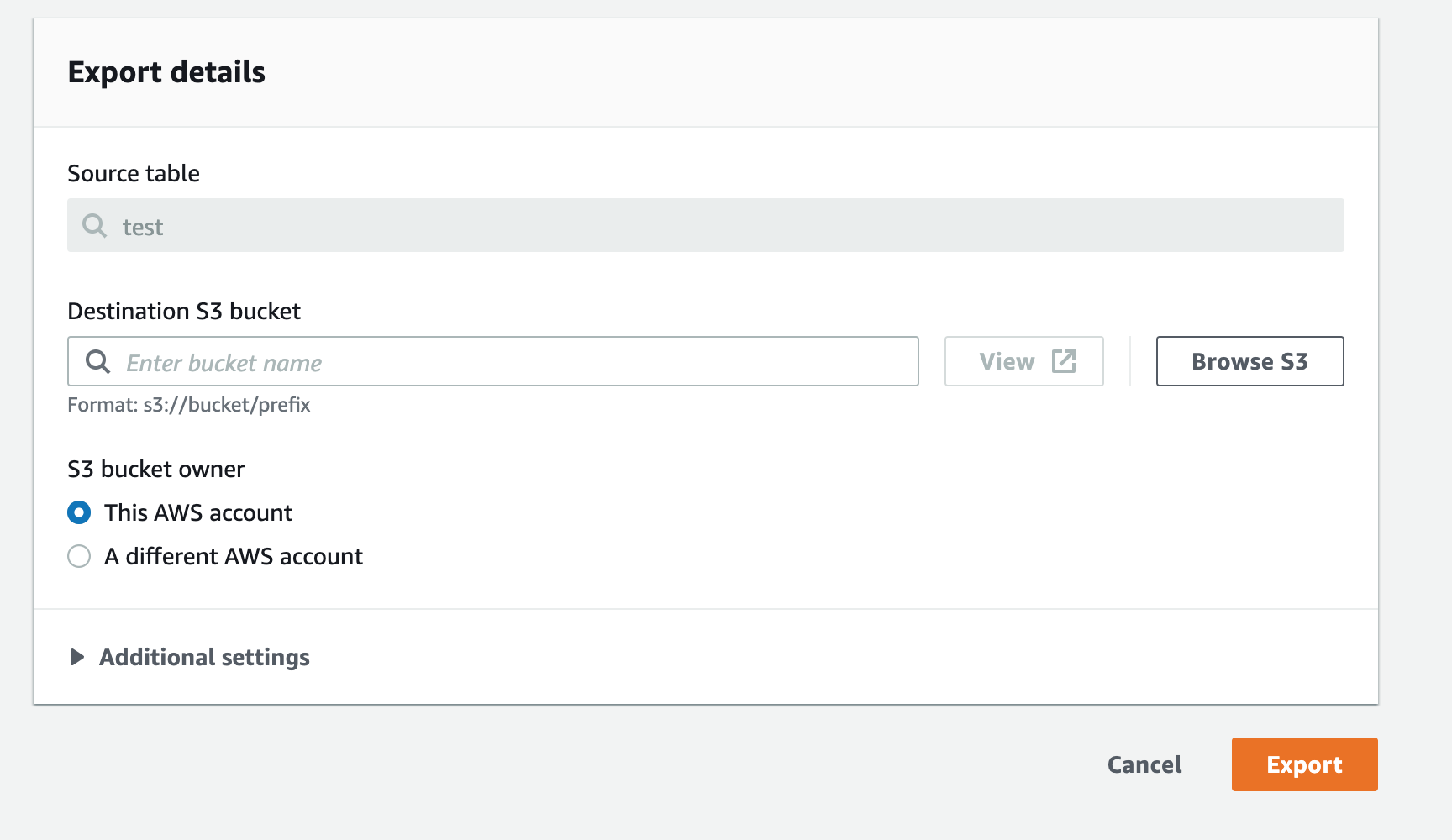
Cross account backup
There are 2 ways to do the cross account backup
- You can choose the different AWS account while selecting the S3 bucket and give permissions according to that
- You can export to an S3 bucket present in the current account and enable CRR (Cross Region Replication) to replicate the objects to another account
Automating the backups on specific intervals
- Create a lambda
- Write code to “Export to S3” using aws-sdk
Example code in JS (using aws-sdk version 3).
const result = await dynamoDB.exportTableToPointInTime({ TableArn: "<>", S3Bucket: "<>" }); - Schedule the lambda run using CloudWatch event rules (using schedule cron or rate expressions)
How to restore the backup?
There is no direct import option similar to export option as above. Hopefully AWS will come up with straight forward import to DynamoDB. But for now, we have to manually read the data from S3 objects and insert into the DynamoDB table as part of restore process.
We can use traditional Data Pipelines to restore or Create a script
- Stream backup files from S3
- Each Dynamo item stores as a single line in the backed up file
- Insert these objects into the table using sdk.
What is the Cost of these backups?
This is not a table scan solution, no extra infra/server. So, the cost of this solution is less comparing with Data Pipelines solution.
Taking the example of US east
For PITR - $0.20 per GB-month
For export - $0.10 per GB per export
and additional S3 cost.
Subscribe via RSS